Recently, I've been reading on Apple Books on my computer. The experience is decent, but there's one annoying aspect when taking notes: When you copy content from a book, Books automatically adds quotation marks and appends copyright information. This can't be removed through citation settings, which means that every time you paste a note, you have to manually delete this extra information. It's quite a hassle.
"If there is evidence that allocating empty sets can harm performance, it can be avoided by repeatedly returning the same immutable empty set, because immutable objects can be freely shared (Item 17). The following code does just that"
Excerpt From effective java 3rd Chinese edition wizardforcel This material may be protected by copyright.
I looked online and found quite a few people complaining about this. Everyone seems to handle it externally, with the main solution being the use of Automator.
- Don't want iBooks to always paste the "Excerpt From" of what I have copied
- [Mac]Remove citation from iBooks copy-paste
Automator
Automator is an automation tool that comes with macOS. You can arrange actions inside it to automate operations.
For our need to remove copyright information, the overall idea is as follows:
- Get the text content from the clipboard.
- Extract the original text content from the text.
- This can be achieved through a JavaScript script.
1 2 3 4 5function run(input, parameters) { // Your script goes here let matched = input.join('').match(/“([^”]*)”/); return matched[1]; } - Return the extracted content back to the clipboard.
It sounds simple, just like the three steps to put an elephant into a fridge.
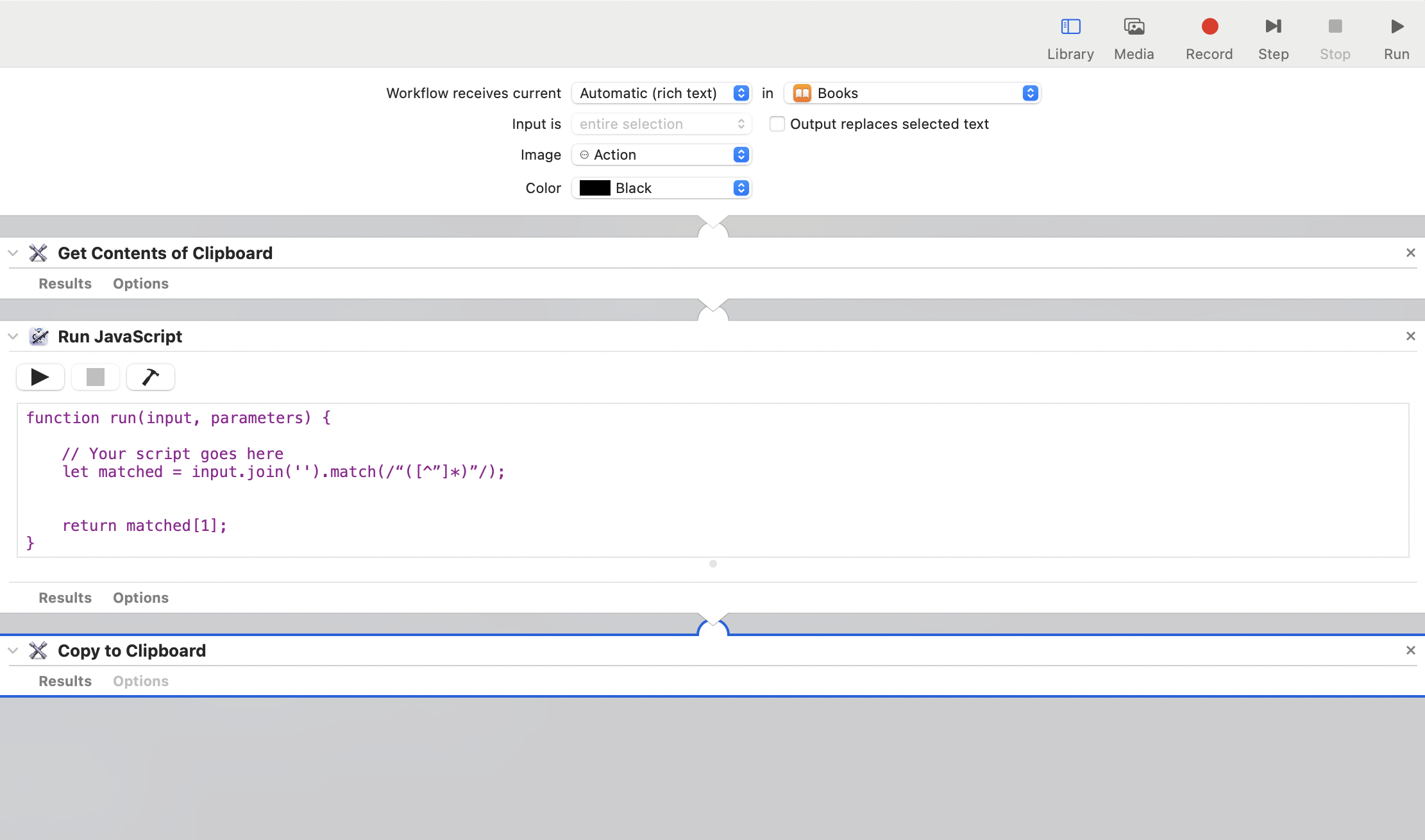
After setting up Automator, you can add a shortcut to the new service (Quick Action) in the system's shortcuts, and then trigger it in the application. However, after setting it up, no matter what shortcut I tried, I couldn't trigger it successfully, so I gave up on this method.
Raycast
Since we're using scripts anyway, why not go through an extra process and use Raycast to write a script for the conversion? This way, we don't have to set and remember extra shortcuts.
After copying the content from Books, execute the Raycast script to convert the clipboard content. The main trouble here is that Node.js does not natively have an API to directly access the clipboard. Here, I borrowed the implementation of clipboardy, which accesses the clipboard by calling command line commands.
| |
It's straightforward: use exec to execute command line commands to get clipboard content, then use regular expressions to extract the text content, and write it back to the clipboard after successful extraction. What's even better is that the above code was directly written by ChatGPT for me.
Although the code looks simple, debugging took me a long time. At first, I directly ran the script in the command line after writing it, and it worked fine. However, when I started it from Raycast, the result was problematic, and I couldn't match it no matter what. After logging the full text output, I found that the output was garbled. Obviously, there was an encoding problem. In the end, I manually added env: { ...process.env, LANG: "en_US.UTF-8" } to set the environment variable for encoding, and the problem was solved. It seems that AI is still not familiar enough with the Chinese environment 😂
After adding this encoding environment variable setting, the problem was solved 🛫, and I can continue to enjoy reading and taking notes on Books.