在使用学习了一段时间 JavaScript 之后,对那种在数据源后使用 lambda 函数进行链式的处理方式感到很爽,并带有点病态的沉迷感觉,啥事都想套个 map 或者 filter 来完成。在回到 Java 的学习后,发现自 Java 8 之后,其也开始提供 lambda 函数,并且提供了一些十分便利的 API,主要是 stream API,可以通过这些 API 对于 Collections 当中的数据进行比较 functional 的处理。
Functional Interface
Java 当中的 lambda 表示形式主要是通过函数接口的方式,所谓的函数接口为只有一个方法的接口,例如
| |
对于参数为函数接口的方法,我们就可以使用 lambda 函数来代替实际实现接口的具体类或者匿名内部类。 例如在 Java 当中开启多线程,如果使用传统的传入匿名内部类的方法,可能会较为啰嗦,但如果使用 lambda 表达式,可以很好地简化代码
| |
lambda 函数的参数类型和返回类型,除了可以通过编译器隐式推导以外,还可以显式指定参数类型。
package function
在 Java 的 标准库 java.util.function 当中提供了许多的函数接口可供直接使用,例如
Predicate: 判定谓词函数testConsumer: 接收输入参数,无返回值acceptFunction: 接收参数,返回参数applyOperator: 运算符applySupplier: 无输入生成返回get
这些函数接口还分别提供了泛型版本,基本类型版本(IntFuction, BooleanSupplier),以及多元版本(BiFuction, UnaryOperator)
使用函数作为参数
在官方库出了相关的函数接口 java.util.function 之后,设计接收函数作为参数的函数就变得更为简单了。
| |
must immutable
lambda 当中使用的外部变量必须为 final 或者是事实上是 final 的,否则会编译不过,例如下面的例子,需要一定的 workaround。
| |
函数引用
在某些时候,可以使用已有的方法传入到函数接口参数当中,例如
obj::methodString::lengthString[]::new
这样的设计大概是因为如果在 lambda 函数当中使用了外部 mutable 的变量,当这些变量被修改时可能会导致 lambda 函数实际执行时结果与预期不一致,例如可见 循环体中局部变量的小坑
Stream API
stream API 主要用于对于 Collections 的数据进行操作,主要是通过链式的调用各种操作,最终获取想要的结果。其具有以下的特点:
- 无存储。stream 是数据源的一个试图,并不会在中途产生一个保存数据源中数据的结构
- 函数式编程。使用的方式非常函数式编程,大量使用函数接口传入函数,每个 API 也使用 Fluent API 的方式返回 stream 实现链式的调用
- 惰式执行。stream 的操作并不会立即执行,只有等到用户真正需要结果的时候才会执行。
- 可消费性。stream 只能被“消费”一次,一旦遍历过就会失效,就像容器的迭代器那样,想要再次遍历必须重新生成。
一个简单的例子:找出学生列表当中年龄大于 20 的学生,并获取他们的名字列表
| |
如果是写循环实现,可能就比较繁琐,需要初始化一个新的 List,遍历源数据当中的每个对象,判断年龄属性,如果满足则获取其名字属性并调用 List#add 方法将其添加到 List 当中。
stream 方法
stream 的方法分为两大类:
- intermediate operation: 不会实际进行计算,会返回一个新的 stream
- map: 对每个元素处理并返回新的元素
- reduce: 对元素逐个进行规约
- filter: 元素过滤
- distinct: 元素去重
- sorted: 元素进行排序
- terminal operation: 马上进行计算获取 stream 的结果,调用后 stream 失效
- count: 计数
- max/min: 获取最值
- forEach: for 循环的 fuctional 写法
- findFirst: 找第一个元素
- toArray: 转成数组
- collect: 把 stream 当中的元素收集到某个容器
collect
我们使用 stream 进行数据的处理,在大多数的时候还是想要从一个数据源当中获取到我们想要的数据,而这些想要获取的数据,除了是一些单个值的数据结果(如计数,最值),大多时候都需要以数据集的形式返回,这个时候就需要使用 collect 方法来对目标数据元素进行收集。
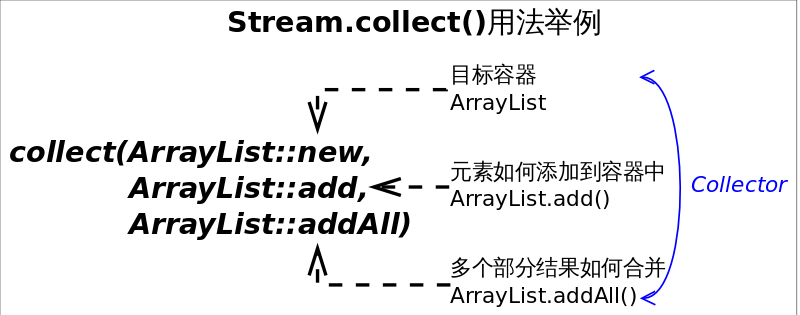
Collect 的原理到底是什么呢?考虑一下将一个 Stream 转换成一个容器(或者 Map)需要做哪些工作?我们至少需要两样东西:
- 提供容器的方法
- 往容器添加元素的方法
- (如果是支持并行的话,还需要提供多个部分结果如何进行合并
所以 collect 的方法的其中一个定义如下,三个参数分别对应三个部分
| |
以下是将 stream 中元素收集到一个 ArrayList 的 collector 例子
但是每次都传入三个函数接口参数着实比较麻烦,于是就设计出可以使用 Collector 对这三个参数进行一个封装,有以下的定义
| |
官方的 Collectors 工具类提供了静态方法生成各种常用的 Collector
| |
map 的生成
如何使用 stream 来生成 map?可以使用 collect 方法在特定的 collectors 当中
- 使用
Collectors.toMap()方法。参数为 key 和 value 的生成函数 - 使用
Collectors.partitioningBy()。可以根据一个 predicate 函数将元素二分 - 使用
Collectors.groupingBy()。类似 sql 语句当中的 group by
| |
其中 groupingBy 方法还能像 sql 当中的 group by 一样进一步对于分组之后的元素进行处理。通过使用下游收集器,可以对于元素进行进一步的处理,例如分组之后对每组元素进行最值的查询或者计算平均值
| |