最近在电脑上使用 Apple Books 看书,体验还可以,但就是做笔记的时候有个很烦人的地方:复制书本内容时,Books 会自动给复制的内容加上双引号,并且加上版权信息。而且这还不能通过引用的设置去除,导致做笔记摘录时每次粘贴后都还要手动去删除,麻烦得很,
“如果有证据表明分配空集合会损害性能,可以通过重复返回相同的不可变空集合来避免分配,因为不可变对象可以自由共享 (条目 17)。下面的代码就是这样做的”
Excerpt From effective java 3rd 中文版 wizardforcel This material may be protected by copyright.
上网搜了一下,还是挺多人吐槽的,大家也只能通过外部的手段来处理,主要看到的解决方案都是用 Automator.
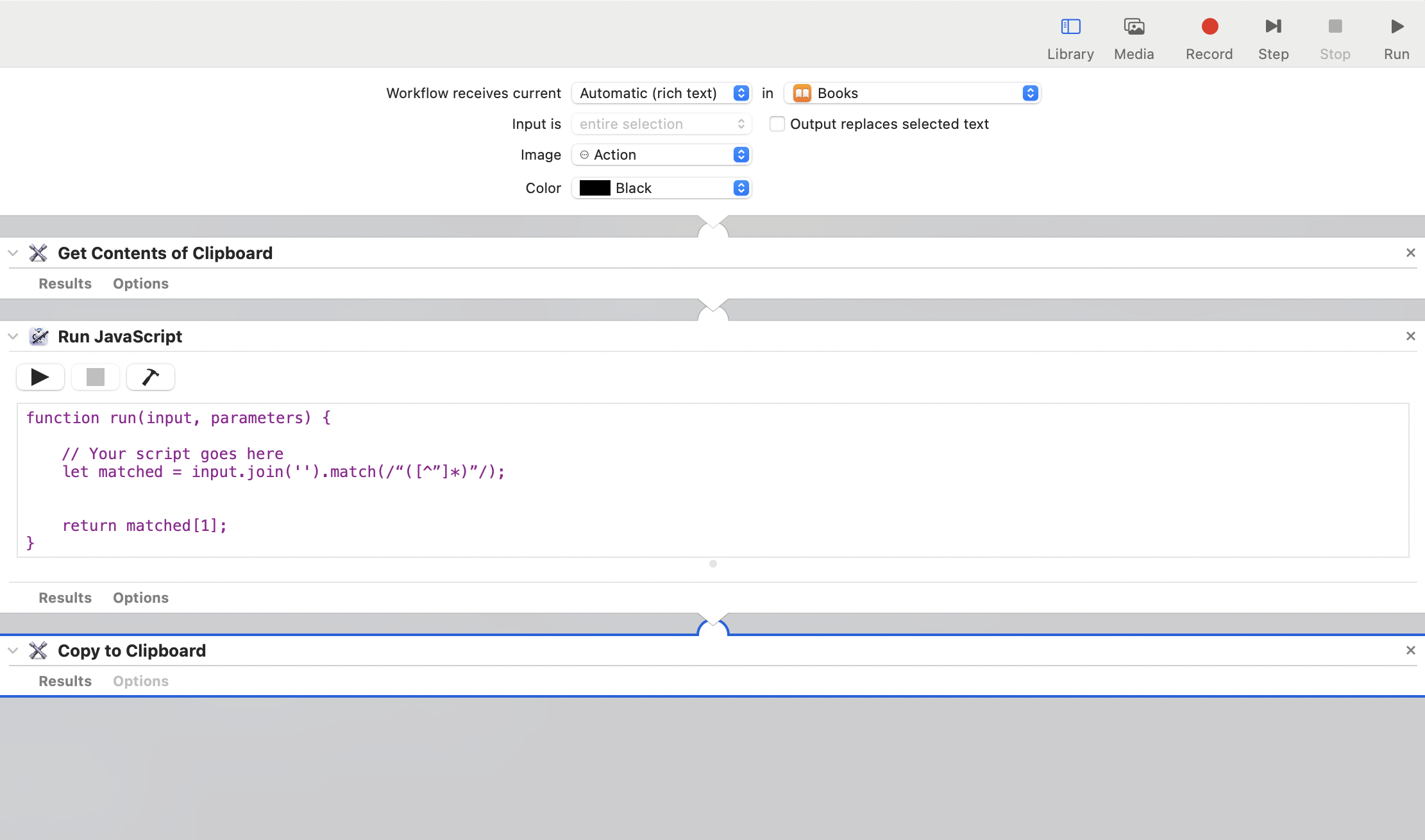
Automator
Automator 是 macOS 上附带的一个自动化工具,可以通过编排里面的 action,实现自动化的操作。
对于我们这个去除版权信息的需求,整体的思路就是
- 获取剪贴板中的文本内容
- 将文本内容中原始的文本内容取出来。
- 可以通过 JavaScript 脚本来实现
1 2 3 4 5function run(input, parameters) { // Your script goes here let matched = input.join('').match(/“([^”]*)”/); return matched[1]; } - 将取出来的内容返回入剪贴板中
听起来很简单,就像将大象放入冰箱一样三步完成。
设定好 Automator 后,就可以在系统的快捷键中,为新设置的服务(Quick Action)添加一个快捷键,然后在应用当中触发。但是我在设置好后,无论换怎样的快捷键,都没有办法能够触发成功,最好放弃了这个办法。
Raycast
反正都是用脚本,不如多走一个流程,干脆直接用 Raycast 写个脚本做一次转换?这样还不用去设置和记忆额外的快捷键。
在复制了 Books 当中的内容后,执行 Raycast 的 script 对剪贴板内容做一次转换。这里主要麻烦的地方是 nodejs 原生其实没有直接访问剪贴板的 API。这里就借鉴了一下 clipboardy 的实现,通过调用命令行命令,访问剪贴板。
| |
简单直接,通过 exec 执行命令行命令获取剪贴板内容,然后通过正则表达式抽取其中的文本内容进行抽取,抽取成功后再写入到剪贴板当中。更爽的是,以上的代码还是直接由 ChatGPT 帮我写的。
虽然代码看起来简单,但是调试起来却让我踩坑了很久,一开始写好直接在命令行运行脚本,运行没问题,以后好了,但是从 Raycast 发起,得到的结果确实有问题,怎么都匹配不上。后面通过打日志输出全文才发现,输出居然是乱码,很显然是编码问题,最终人工加上了 env: { ...process.env, LANG: "en_US.UTF-8" } 设置环境变量设置编码,问题解决。看来 AI 还是不够熟悉中文环境 😂
加上这个编码环境变量设置后,问题解决 🛫,又可以继续爽快地看 Books 做笔记了。